《Cognitive Electronic Warfare An Artificial Intelligence Approach》第五章的读书笔记。
目录
大多数电子战文献将EP和EA的讨论分开,因为它们目的不同。但从人工智能的角度来看,它们可以使用相同的底层算法和解决方案。
EP和EA之间的唯一区别是任务目标:EP针对己方的目标,而EA针对敌方的目标。例如,EP可能想要最小化BER,而EA的目标是最大化POI;BER可以直接测量,而POI不能。
电子战系统要求在各种可能的环境下,选择行动来实现任务目标。认知决策者将已有功能组合成策略以实现目标。任务类型包括:规避、防御、欺骗、破坏、毁灭等。
人工智能应用于EA和EP的优势是处理速度快和可处理的复杂度高。
图1说明了一个概念性的流程。决策者从ES系统中获取输入,该ES系统包括观测数据$O$和效用$m$的最新反馈,并选择要实施的策略$S$。
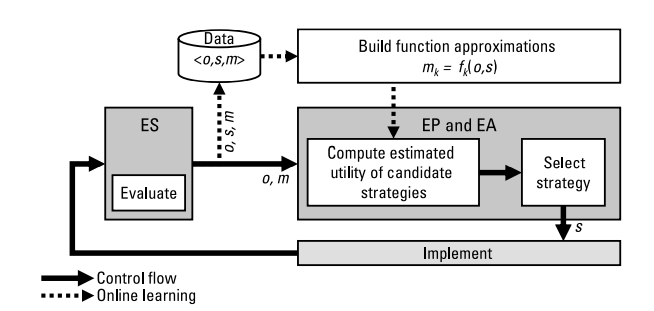
选择最优策略的方法是使用决策理论方法,它遵循关于行动选择的严格推理方法。在一个认知电子战系统中,决策理论有三个高度相关的概念:计划、调度和优化。
• 计划综合了一系列行动,以实现所需的目标状态。是指要做什么,以及按什么顺序进行。
• 优化对多个计划进行评估,以选择“最优”计划。综合电子战系统优化EP和EA指标,如功耗、检测概率和电子战BDA。(5.1节)
• 调度是将排序的计划映射到特定资源和时间批次。(5.2节)
只有通过动态协调各层才能保证解决方案的可行性。本章介绍如何选择策略,重点是优化和调度。5.1节介绍了优化方法,5.2节讨论了调度,第5.3节描述了DM的一个理想属性:可中断性,第5.4节考虑分布式节点网络优化的方法。
1. 优化
优化问题是选择一组最大化(或最小化)效用函数的值。
1.1 多目标优化
不可能同时优化所有目标,因此系统必须在各种目标之间进行权衡,使所有目标都有足够的性能。例如,速率/范围/功率之间的权衡,稳定性和效率之间的权衡。
当目标之间的期望平衡未知时,帕累托最优边界是每个目标的非劣解集合。使用以下常用方法可得出“最优”决策:
• 以目标函数形式定义所需平衡的任务参数(2.4节);
• 建立约束模型,其中一些指标必须满足最低标准,而另一些指标则是可优化的;
• 计算期权上的概率分布(6.2节);
• 向操作员展示可行的选项(第6.3节)。
1.2 随机优化算法
人工智能解决了如何解决指数级运算的性能问题。
根据目标函数的定义,EW具有指数数量级的策略($Π_{∀_{c}v_c}$,其中$v_c$是控制参数$c$的可能值的数量),接近无穷大。当策略的数量很少时,系统可以估计每种策略的效用,但随着战略数量的增加,替代方法变得必要。在目标函数光滑且局部极值存在的情况下,基于梯度的选择是一种有效的求解方法。
但是电子战的目标很少是平滑的,也不一定是连续的,经常有许多局部极值,这需要用到随机搜索方法。也称为元启发式方法(metaheuristic methods)、蒙特卡罗方法或随机算法,它们在统计上保证最优解,但通常没有办法知道它们是否找到了最优解。
电子战中对随机化优化算法的使用还不充分,文中列举了一些例子。$^*$
几种随机优化算法:
• 蚁群优化(ACO)是一种求解组合优化问题的通用的元启发式算法。一群人工“蚂蚁”将搜索随机化的某一个解。当蚂蚁在地貌中移动时,它们会留下“信息素”,更高概率的路径会有更密集的“信息素”。
优点:蚁群算法本质上是可并行化的,保证收敛,并且可以在动态应用中使用。
缺点:由于蚁群算法是随机搜索,收敛时间是不确定的,理论上很难分析,也不能保证有最优解。前一次迭代中的最优解增加了后续迭代中的解将遵循相似路径的概率,从而降低了策略的多样性。
在认知无线电网络中使用蚁群算法来构建路由树、分配信道和调整传输参数。
• 粒子群优化(PSO)使用候选解(粒子)的群体(群)在搜索空间中移动。粒子的移动是由它们自己对自己位置的估计和群体中心位置来指导的。
优点:PSO的结构简单,易于编码。粒子群算法比遗传算法更有效,特别是在求解连续变量问题时。粒子群算法可以在动态应用中运行。
缺点:PSO参数的选择会对优化性能有很大影响,并且可能过早收敛到局部最优值,特别是在问题复杂的情况下,随机变异性可能非常高。
PSO用于计算无线网络中传输和资源分配的多参数解决方案;对于雷达脉冲压缩编码和离散频率波形的设计效果很好。
• 遗传算法(GAS)是另一种基于群体的随机搜索方法,其解被编码为“染色体”。这种混合启发式算法使用变异、交叉和选择来生成复杂问题的最优解决方案。
优点:遗传算法适合处理离散值问题,并且很容易并行化。
缺点:遗传算法容易过早收敛,不一定能保证策略的多样性;编码是特定于问题的,这些编码可能很难创建;遗传算法的计算效率也不如粒子群算法。
GAS用于计算传输的多参数解决方案,目标包括电源管理、传输性能和共享频谱使用。气体已用于雷达设计、波形选择、目标识别和干扰抑制等。
• 模拟退火(Simulated annealing)是另一种随机优化算法,它概率地决定是否从一个解转移到另一个解。与GAS和PSO不同,它只有一个搜索个体。选择概率函数时,当解决方案质量差异增大时,决定移动的概率会降低;也就是说,小的上坡移动比大的上行移动更有可能。该算法可应用于遗传算法和粒子群算法中,以提高搜索速度。
优点:模拟退火相对容易编码,通常能提供较好的解决方案。(从统计上讲,它可以保证找到最优解决方案),因为模拟退火只有一个个体,所以它比基于种群的方法需要的内存要少得多。
缺点:它很有可能落到开始时所在的那个”最优山谷“里;它不知道自己是否找到了最优解决方案。
模拟退火已被用于各种主题,如检测天线故障、满足无线电网络的QoS、估计雷达截面、定位干扰器以及抑制干扰。模拟退火和遗传算法结合起来用于雷达成像和设计MIMO传感器阵列。模拟退火可与其他人工智能技术相结合,以提高收敛速度。
• 交叉熵方法(CEM)是一种随机搜索的抽样方法,它从概率分布中抽取样本,然后最小化该分布与目标分布之间的交叉熵,以便在下一次迭代中产生更好的样本。
优点:CEM定义了一个精确的数学框架,在某种意义上是最优的学习规则。它对参数设置具有很强的鲁棒性。CEM对于需要精确估计极小概率的罕见事件模拟是有价值的。
缺点:收敛时间是不确定的;原始的CEM方法具有很高的存储和计算要求。
CEM用于估计和优化网络可靠性,寻找网络路径、天线设计问题等。与模拟退火一样,CEM可以与基于种群的方法相结合来并行化解。
1.3 优化元学习(Metalearning)
元学习(Metalearning)是一个学会学习的过程。元学习是对学习现象的认识和理解,而不是对任务目标知识的学习。元学习者改变算法的操作参数,以使其预期性能随着经验的增加而提高。
元学习是通过学习来学习的。许多学习算法都是优化器;因此,元学习可以学习优化改进优化器。
元学习的早期研究主要是用于在不同算法之间进行选择,元遗传编程以进化出更好的遗传程序,以及学习优化神经网络中的学习规则。
Metalearning优点:
• 速度:学习或优化的速度更快;
• 易用性:自动调整算法的过程;
• 适应性:对环境变化的敏捷性;
• 减少数据学习过程:很方便的将知识从一种环境转移到另一种环境。
元学习方法可以提高机器学习模型的通用性以及决策引擎的效率和准确性。
元学习可以确定策略选择的优先顺序。该算法搜索一小部分重要控制标签的选项,同时使用默认值或在前一个时间步中选择的值来搜索不太重要的控制标签。仅在确定这些重要值之后再搜索不太重要的控制标签。
元学习可以分析搜索过程,优化超参数,提高搜索效率。元学习者优化控制$U_n$的优化的一组超参数$θ$。元学习者使用元效用函数$(U_n,J)$,其中$U_n$评估优化器的质量,例如收敛速度。
2. 调度(Scheduling)
将确定的计划调度到对应的时间点。在电子战中,调度通常提供何时发送和何时接收的细节。
电子战资源调度器需要的东西:进行的动作序列及其资源要求,使用的资源,约束、效用函数。
关键路径法建立了一个关联行动的有向图,关键路径是总持续时间最长的路径,它决定了整个电子战任务的最大持续时间。位于关键路径上的任何任务都称为关键任务。
在电子战系统中,调度器选择最终使电子战系统能够发送和接收的动作。调度器可以以循环或线性方式执行动作。线性是一次性的,而循环会重复多次。
为了平衡如输出功率、能效和时间要求等众多约束,自动调度器将权重分配给这些约束。
分布式电子战系统的单个节点可能知道其覆盖范围内的所有状态,但可能不知道其他节点或参与者的状态。任务的部分完成可以在每个节点上局部地完成,但节点之间的协调至关重要,因为节点可能不会朝着相同的目标行动,并且可能最终与彼此的目标冲突。设计者的目标是创建一个在任务和约束范围内实现所有调度目标的调度器。
在分布式系统中,决策应该基于各节点的响应,以确定是否需要放弃某些任务,或者是否应该允许另一个节点执行该任务。
调度器必须依赖观测信息,并基于这些信息对任务重新排序。
3. Anytime算法(随时停止算法)
电子战各类算法运行在具有强实时性要求的快速变化的环境中。新的优先事项随时可能“弹出”,资源可能会意外耗尽。决策者的一个理想特征是,它可以快速生成解决方案,或者在有时间的时候,花更多的时间进行再三评估。算法运行的时间越长,找到的解决方案就越好。
理想状态下任何时候算法都可以在计算过程中的任何时刻被中断,以返回其效用是计算时间的函数的结果。灵活计算概念明确地平衡了额外计算时间的好处与产生解的成本。这两种想法都源于Herb Simon的满意概念,该概念涉及寻找解决方案,直到达到可接受的平衡。
大多数元启发式算法都满足这一条件:每次迭代都会提高最佳可用解的质量,并可以根据需要停止。
4. 分布式优化
电子战系统可能需要在单个平台或跨平台上跨多个决策者进行优化。
解决方案根据任务性质而不同:
• 集中式:单个决策者为所有组件和所有节点找到解决方案;
• 分布式:决策者使用本地通信来协调行动;
• 权力下放:决策者完全独立,不依赖通信进行协调。
在单一平台上,单个优化器通常会找到比多个优化器更接近最优的解决方案,因为它可以搜索单个全局解。
在整个平台网络中,单一的集中式优化器是不合适的。原因:如果集中式运算器出现故障,整个系统就会出现故障。还存在其他问题包括决策的延迟、信息隐私等。与其在决策前找到全局最优决策,不如迅速做出一个局部最优的决策。
分布式优化方法在本地邻居之间进行通信,以协调操作。传统的方法假设交流是安全的,这一假设在电子战中并不成立,由于干扰等因素,电子战中通信常受到限制或被拒绝。
• 共识传播是一种轻量级通信方法,它允许每个节点共享其对全局效用的局部估计,并快速计算全局平均值。
• 无通信学习使得局部感知足以确定解决方案是否有效,每个节点只需要知道它自己的分配;它不需要知道其他节点的选择。
分布式优化方法支持信息融合、资源分配和调度。分布式优化的一个常见应用是定时同步,然后可用于数据融合、占空比循环、协作定位和协调动作,如分布式波束成形。
5. 结论
就像机器学习和统计推断一样,优化也存在相同问题:如果一个算法在某类问题上表现良好,那么它在解决剩余问题集上的性能就会下降。
本章介绍了一些被证明对电子战问题有效的优化方法;这些方法支持:
• 支持多个目标;
• 快速搜索指数性能面;
• 处理动态环境;
• 在给予更多时间时提高解决方案质量;
• 在通信受限的情况下,多个节点都能正常运行。
Special offer for antibiotics: buy antibiotics and get discount for all purchased! Two free pills (Viagra or Cialis or Levitra) available with every order. No prescription required, free delivery.
antibioticshiz 2023-10-20
6,can you delivery it to China?
Qianxi 2023-11-03 回复 @antibioticshiz